
Ik ben Victor Margallo, Data Scientist bij PublicSonar. In deze blog introduceer ik de concepten van AI en Data Science en leg ik uit hoe we daar in ons bedrijf gebruik van maken.
Wat is AI?
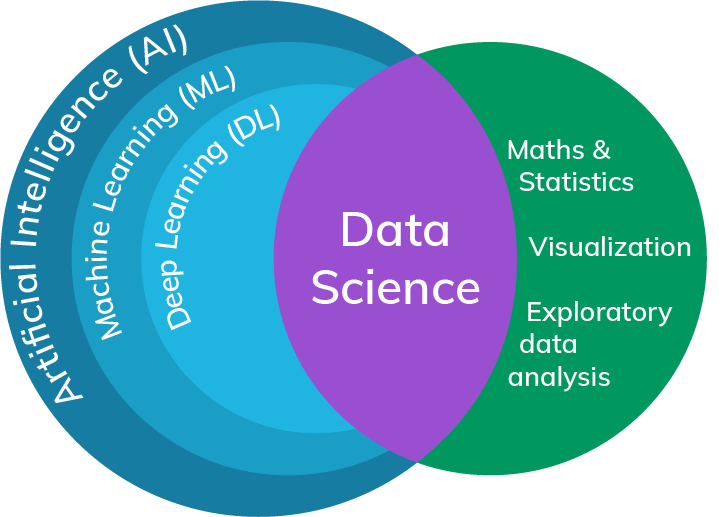
Kunstmatige Intelligentie of Artificial Intelligence (AI) kan omschreven worden als de “programmeerbare logica” of “intelligentie” binnen een computeromgeving. Het concept bestaat al heel lang. Hoewel sommige historici beweren dat oude culturen reeds een concept hadden voor AI als levenloze objecten die konden denken, werd de term pas in het midden van de twintigste eeuw geformaliseerd.
Met het ontstaan van computers konden we beginnen met een deel van ons menselijk denken te vertalen naar machines. . Dit zorgde voor de zeer brede definitie van AI aangezien elke logica die in een computer is geprogrammeerd binnen de definitie valt. Computerwetenschappers, wiskundigen, natuurkundigen, ingenieurs, economen en psychologen zijn sindsdien allemaal bezig met AI.
Waarom al die ophef over AI de laatste tijd?
Er zijn verschillende factoren die AI in de schijnwerpers hebben gezet en die ook bijgedragen hebben aan het ontstaan van Data Science. Deze factoren zijn de democratisering van computers, de opkomst van open-source code en het digitale tijdperk waarin we leven. Met al deze ontwikkelingen heeft Data Science een enorme vlucht genomen.
Hoe verschilt AI van Data Science?
Ondanks het uitwisselbare gebruik van beide termen, zijn ze niet hetzelfde. AI omvat elke vorm van intelligentie in een machine en is daarmee, zoals al eerder gezegd, een zeer breed begrip. Data Science is op zijn beurt een studiegebied waarbij interdisciplinaire vakgebieden zoals statistiek, wiskunde, programmeren en domeinspecifieke kennis betrokken zijn.
We weten dus dat de definitie van AI zeer algemeen is, en ook al is Data Science specifieker in zijn definitie, toch zijn er nog veel onderwerpen in elkaar verweven. Het laatste onderdeel die we zojuist noemden, namelijk domeinspecifieke kennis, zorgt voor het karakteristieke onderscheid dat nog ontbrak. Als je te maken hebt met tekstgegevens, bevind je je in het domein van tekstanalyse of natuurlijke taalverwerking; als beelden het onderwerp van je analyse zijn, heb je beeldherkenning; of misschien heb je tijdreeksgegevens zoals weersvoorspellingen. Zoals te zien is, bestrijkt Data Science een breed scala van gegevenstypes, bronnen, modellen en technieken.
Hoe ziet Data Science er bij PublicSonar uit?
Wij richten ons op tekstuele data en voor het oplossen van problemen gebruiken we verschillende methodes. Afhankelijk van de doelen, varieert onze toolset van traditionele tekstverwerking tot Deep Neural Networks. Met redeneren en experimenteren bepalen we welke methode het beste past en wat de trade-offs zijn.
Een voorbeeld hiervan hangt samen met de verscheidenheid aan bronnen die we analyseren; een model dat naar tweets kijkt, zal waarschijnlijk te maken krijgen met een taalgebruik dat sterk verschilt van het taalgebruik in krantenartikelen. Het is dus belangrijk dat de technieken en modellen die we kiezen, passen bij de gegevensbron(nen), de complexiteit van het probleem en de technische integratie om het bruikbaar te maken.
Hoe kan Data Science helpen bij crisis- en incidentmanagement?
De eerste stap om een incident te volgen en managen met publieke data is het creëren van een goede zoekopdracht. Daartoe heeft PublicSonar een model ontwikkeld dat je helpt bij het bedenken van woorden die lijken op de woorden die je als eerste opschrijft. Op deze manier kun je snel relevante woorden aan de zoekopdracht toevoegen en de bouw van je zoekopdracht verbeteren.
Wanneer de zoekopdracht staat, is de piek in het aantal inkomende berichten één van de vaste uitdagingen bij crises en incidenten. Data Science kan helpen om een enorme hoeveelheid informatie te verzamelen door lange tekstinhoud samen te vatten. Evenals belangrijke tekstelementen te extraheren zoals dagen, tijdstippen, locaties, politieke entiteiten, personen of andere unieke kenmerken. Ook kan Data Science helpen bij het weergeven van de onderliggende sentimenten in de tekstberichten.
Daarnaast werken wij aan modellen die leren om informatie te herkennen voor specifieke use-cases. In het geval van een aanslag bijvoorbeeld, zoeken de modellen binnen alle berichten gericht naar specifieke belangrijke gegevens. Denk hierbij aan het aantal slachtoffers, de plaats, kenmerken die duiden op de aard van het ongeval of aanslag, het soort aanslag, de fase van de gebeurtenis of relevante informatie over de dader.
Hoe kunnen we deze modellen trainen en aanleren?
Veel van onze modellen hebben gegevens nodig die door mensen zijn geannoteerd om te leren hoe ze de taak moeten uitvoeren. Een groot voordeel van PublicSonar is onze in-house annotatie. Wij hebben een team van annotators samengesteld dat voortdurend onze bestaande en nieuwe modellen traint en actualiseert. Bovendien verwerken we ook de deskundigheid van onze gebruikers, zodat zij de uitkomsten van onze modellen kunnen aanscherpen. Ook hierdoor neemt de kwaliteit van de resultaten over tijd steeds verder toe.
Wat zijn de uitdagingen van Data Science?
Machine Learning en Deep Learning modellen brengen een aantal uitdagingen en gebreken met zich mee waar iedereen zich bewust van moet zijn, vooral als je ermee werkt.
Het eerste punt is dat het geen hersens zijn die kunnen redeneren. De modellen voeren slechts de taken uit waarvoor ze zijn opgeleid. Ze kunnen geen nieuwe taken of kennis leren tenzij we ze daartoe trainen of klaarmaken Voor sommige taken slagen modellen er niet in te handelen zoals mensen.
Het tweede punt heeft betrekking op de bias van het model. Zoals we eerder aangaven, leren veel van onze modellen op basis van menselijke voorbeelden. Als die voorbeelden fout zijn of een menselijk vooroordeel bevatten, zal dat ook de uitkomsten van het model beïnvloeden. Dit probleem wordt nog groter wanneer voorbeelden van verschillende mensen worden gebruikt. Je kunt denken aan een baby die van zijn moeder te horen krijgt dat wat hij deed goed was en van zijn vader dat het slecht was; dat is contraproductief en verwarrend voor een lerend brein. Menselijke vooroordelen zijn heel subtiel en soms moeilijk te doorgronden. Neem bijvoorbeeld de Microsoft Tay, een interactieve chatbot, die in 2016 werd uitgebracht. Pas na interacties met echte gebruikers realiseerden ze zich dat Tay inherent racistisch was doordat ze getraind was met de verkeerde Twitter data. Waar het op neerkomt is dat het model de onderliggende voorbeelden zal nabootsen. Het is daarom dus belangrijk om het model correct te trainen en vertekeningen snel te ontdekken en te corrigeren.
Het derde en laatste punt is dat hoe complexer de modellen zijn, hoe moeilijker het is om de interne werkwijze tot het uiteindelijke resultaat te begrijpen. Om niet alleen de bias te herkennen maar ook te begrijpen hoe deze heeft kunnen ontstaan. Dit kan een moeilijk proces zijn. Daarnaast is het kunnen redeneren zoals mensen dat kunnen heel waardevol voor het duiden van informatie. Deep Learning-modellen slagen hier op dit moment (nog) niet in waardoor het een uitdaging kan zijn om de context van de informatie goed te begrijpen.
Ervaren hoe AI in de praktijk gebruikt wordt?
Vraag vrijblijvend een demo aan!



