
I’m Victor Margallo, Data Scientist at PublicSonar and in this blog post I would like to briefly introduce the concepts of AI and Data Science and how we make use of them in our company.
What is AI?
Artificial Intelligence or AI is the field of programmable logic or intelligence in a computing environment. AI has been with us for a long time. Even though some historians claim that ancient cultures already had a concept for AI as inanimate objects that could think, it was not until mid-twentieth century that the term was formalised.
With the birth of computers, we were able to start to translate some of our human thinking into the machines. This is a very broad concept as it opens up the definition of AI to every logic programmed in a computer. Computer scientists, mathematicians, physicists, engineers, economists, psychologists etc. They all have been doing AI every day since.
So why all this buzzing around AI lately?
There are several factors that brought AI in the spotlight and they are related to the origin of Data Science as well. These elements are the democratization of computing resources, the rise of open-source code and the digital age we live in. With all these developments Data Science boomed.
How is AI different from Data Science?
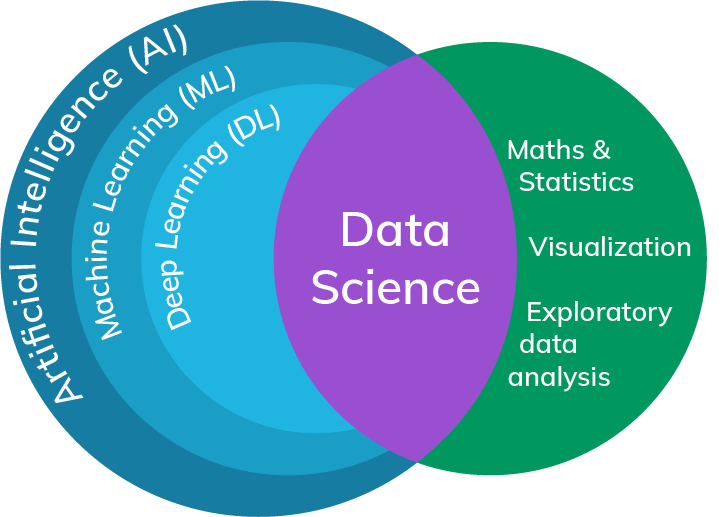
Despite the interchangeable use of both terms, they are not the same. AI is any kind of intelligence in a machine; thus, as we said beforehand, a very broad concept. However, Data Science is an area of study involving interdisciplinary fields such as statistics, mathematics, programming and domain specific knowledge.
We know AI is very general to define globally and capture everything, and even though Data Science is more specific in its definition, it is still entangling many topics. Yet, it is the last field we mentioned, domain knowledge, the one that brings the specificity that we were missing. If you are dealing with text data, you are in the domain of text analytics or Natural Language Processing; if images are the subject of analysis, you have image recognition; or maybe you have time series data as for weather forecasting. As you can see, Data Science covers a wide different menu of data types, sources, models and techniques.
What does Data Science look like in PublicSonar?
We are focused on text data and to solve the problems we make use of different approaches. Depending on the scope of what we want to achieve, we may vary our toolset from traditional text processing to Deep Neural Networks. And that is because we can’t, unfortunately, have a one-stop shop to fix everything. So we need to experiment and reason well what the best implementation is and what the trade-offs would be if several possibilities are present.
An example of this comes with the diversity of sources we analyse; a model looking at tweets will probably have to deal with a language that differs greatly from the one written in newspapers articles. In general, the techniques and models we choose need to suit the data source/s, the complexity of the problem and the engineering integration to make it usable.
How can Data Science help crisis and incident management?
The first step to manage and monitor an incident with public data is to create a good query. For that PublicSonar has developed a model that helps you come up with similar words to the one you originally wrote. This way you can quickly click and add relevant words to the query and improve the whole query building process.
Once you have your query built, one of the recurrent scenarios in crises and incidents is the spike in number of incoming messages. Data Science can help you synthesize a vast quantity of information by summarising long text content; extracting key text entities such as dates, times, locations, geopolitical entities, persons or other unique references; and show you the sentiment present in the text messages together with the main topics relating to it.
We are also working on models that learn to extract information for specific use cases. For instance, in the event of an attack the models would go through the messages and extract key information like the main event, casualties, where it happened, the type of attack, the status of the event or some relevant information about the perpetrator.
How to train and teach these models?
Many of our models need data annotated from humans in order to learn how to perform the task. One major advantage in PublicSonar is our in-house annotation. We have built a team of annotators that are constantly teaching and updating our current and new models. Furthermore, we also leverage the domain expertise from our users so that they can correct our models’ extractions, improving the results quality over time.
Data Science challenges?
Machine Learning and Deep Learning models carry on some challenges and flaws that everyone should be aware of, especially when working together with them.
The first point is that they are not reasoning brains. These models perform the tasks for which they are trained, they cannot learn new tasks or knowledge unless we first train and prepare them to do so. Thus, models fail to deliver a human-like experience for some tasks.
The second point refers to the model bias. As we said previously, many of our models learn from human examples. If those examples are wrong or contain any kind of human bias so will be the model’s performance. This problem accentuates when using examples from different humans. We can think of a baby being told what he did was good from the mother and bad from the father, it is counterproductive and confusing for a learning brain. Human biases are very subtle and hard to realise sometimes. As an example, in 2016 Microsoft released Tay, a conversational bot. It was not after real life users interactions with the Deep Learning bot that they realised Tay was inherently racist due to being trained with the wrong Twitter data. The bottom line is that the model will mimic the underlying examples. It is important to educate the model correctly and spot biases soon so that we can correct them.
The third and last point is that the more complex models are, the harder it is to understand the inner workings for the final result given. This relates to the introduction of bias and the difficulty of first, spotting it, and second, understanding how it happened. The flow of thoughts from human reasoning is also very informative as it gives us more context, however, it is something Deep Learning models fail to deliver for the moment.
Do you want to experience how AI is used in real life cases?
Request a free demo!



